Overview
We use a straightforward design to condition the pre-trained Stable Diffusion on ID features. The ArcFace embedding is processed by the text encoder using a frozen pseudo-prompt for compatibility, allowing projection into the CLIP latent space for cross-attention control. Both the encoder and UNet are optimized on a million-scale FR dataset (after upsampling), followed by additional fine-tuning on high-quality datasets, without any text annotations.
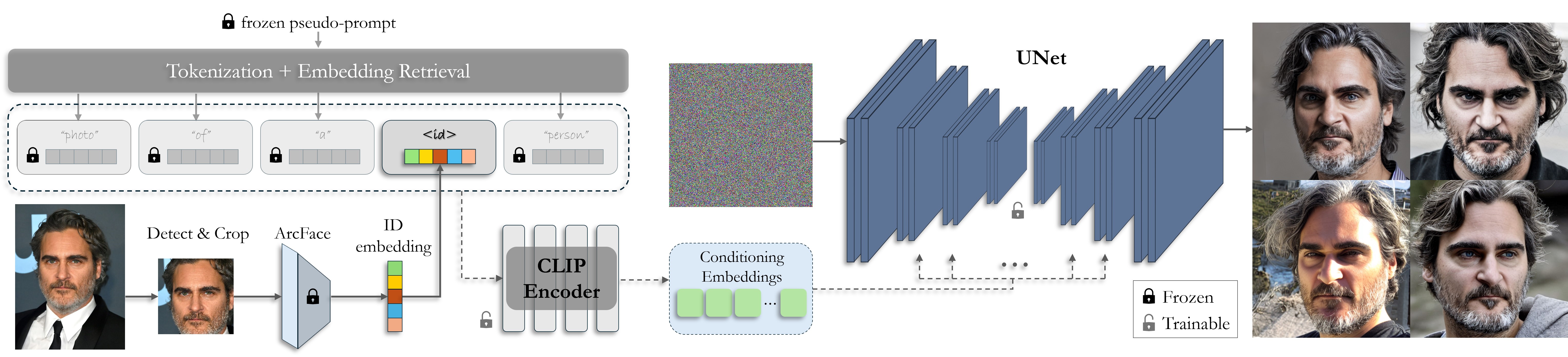
Through extensive fine-tuning, we effectively transform the text encoder into a face encoder specifically tailored for projecting ArcFace embeddings into the CLIP latent space. The resulting model exclusively adheres to ID-embeddings, disregarding its initial language guidance.


